

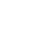
I Tried to Find the ‘Arousal Intelligence’ In An Animated, Augmented Reality Porn Star

Sometimes people—especially those in the field of public relations doing a pray-and-spray campaign, but also small-time developers, the occasional delusional vibe-coder, and local dipshits—deliver messages to my inbox like a cat dropping a dead mouse on my doorstep. For the most part, I resist the bait: often, bad press is still press to these people, or I’m just too busy to really look at the pitch or try the product.
This week, I’m coming back from a week of being entirely offline. I didn’t look at the news or my inboxes for seven straight days. I’m feeling properly healed, and also like I need to retraumatize myself back into the swing of things. Lucky me, on Monday morning, someone representing EnjoyMeNow emailed me about “a mobile website that places a photorealistic 3D character in your real room using augmented reality” using something called “Arousal Intelligence” and “real-time physics,” which streams “in a full engine from a global delivery network.” This press release, sent from “a globally focused media and entertainment holding company pioneering technology-driven innovation across digital platforms worldwide” called DCBG Group which represents EnjoyMeNow, was very thrilling to read as someone who appreciates the art of a good word salad. I dropped what I was doing (deleting hundreds of other emails) to try it out.
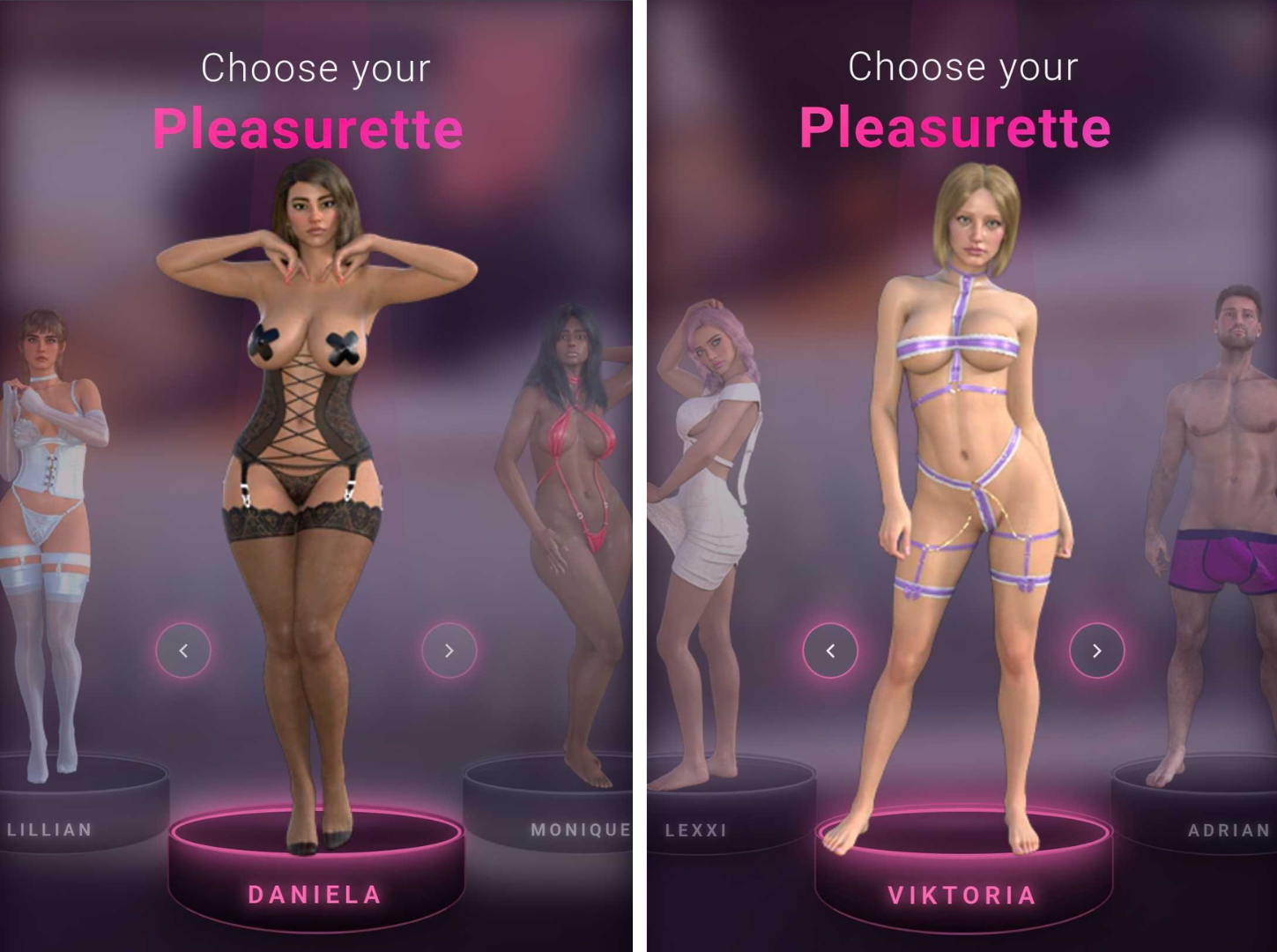
Once on the EnjoyMeNow.com mobile site, after agreeing that you’re over 18, you’re asked to choose a “Pleasurette™,” a gender neutral term for a series of 3D characters and a trademark filed two weeks ago. These include five women wearing sex toy store package lingerie, and one dude, Adrian.
“Every character—called a Pleasurette™—is a photorealistic digital human built from scratch with realistic skin shading, multi-pass rendered hair, and soft-body physics. No real performers are filmed, recorded, or motion-captured. The characters are created entirely in 3D software.” Presented without comment are the Pleasurettes™:
I choose Adrian first because I’m always curious how AR and VR porn copes with the fact that hovering pecs and an immobile penis are difficult to make sexy in this format, real or not. A lot of porn made for a VR or AR experience is shot from the penile point of view: It’s just easier to strap a 180 degree HD camera to a man’s face and tell him to hold still while a female performer is free to writhe around on top than vice-versa. Knowing this, and also knowing that the market for AR/VR porn caters heavily toward men (save for a few beacons of light, such as director Anna Lee, who a few years ago said of the proliferation of male-gaze VR porn: “You’re making the same stereotypical porn you made with a fucking camcorder. It’s the same MILF bending over in the kitchen to bake cookies”), I still went in hopeful. After all, they pitched me.
But it became clear almost immediately that Adrian is not playing for my team, so to speak, and getting the full EnjoyMeNow experience as intended requires equipment I don’t have. To get your chosen Pleasurette™ into your camera’s view, you have to hold your phone at an angle toward your crotch and stroke your penis. Helpfully, since I don’t have one of those, the app overlays a semi-transparent image of a penis at the bottom of the camera. It waits for you to put your hand in frame near the penis-guide to let the show begin. Moving my hand across the camera unlocks the start button. It’s not doing this to make sure you’re choked up on it before starting; It’s calibrating the position of the 3D model to your hand’s location and size, because that’s what controls its interactive aspects.
Without getting too graphic in a blog that’s already pretty explicit so far, this is what I encountered: Adrian walks into view totally nude, leading with his 3D dick at a 90 degree angle, and says “look up, here I come.” Tearing my eyes away from this perfectly straight tree branch and pointing the phone camera up as commanded, with more than a little trepidation, I see the jiggliest pair of male titties I’ve ever seen on screen, nipples wobbling independently of the rest of him. “Stroke back and forth your big dick,” he says, grammatically confounding me on top of already freaking me out with a thousand yard stare. When I make a jerkoff motion in his general direction, he squats up and down like he’s teabagging me in Halo. Bizarrely, when I do this, his entire body shrinks, my hand now a monstrous size in comparison to his penis. No judgement, but he moans in a woman’s voice. “Come on my back soon,” he says, before a screen interrupts the session saying I need to pay $2.99 to unlock more features, such as making my Pleasurette™ orgasm. (For the record, I tried two payment methods to fork over this low low price, both rejected.) The experience is the same with the other characters, just in different skins: the female characters crawl around and squat over my ghost penis, and I use my imagination to jerk it off, which ends up looking like I’m fistbumping tiny 3D women in the vagina. Sometimes, I clip through their hollow bodies and can see straight up into their heads or down through their labia.
0:00
EnjoyMeNow’s PR rep claims that this interactivity is a world first. “Existing AR adult content is pre-rendered video or static models you look at,” they told me. “EnjoyMeNow is interactive, where the character responds to your hand in real-time, placed in your actual room through your phone camera. And it runs entirely in the mobile browser. No app, no download, no account. That combination doesn’t exist anywhere else from our research over the past year of creating this.”
Companies like SexLikeReal and Naughty America have been doing AR and VR content for years, often featuring real porn performers. But this hand-tracking thing EnjoyMeNow is doing is different than that, they claim. And I’ll concede, yes, moving your hand up and down definitely makes the 3D model move around a little bit. Here’s how one of the femme characters acts:
0:00
What really makes EnjoyMeNow stand apart from plenty of other AR porn products is this insistence that not employing real models or performers makes it better or smarter, somehow. On Monday, the DCBC Group’s website said of the choice to use CGI instead of people: “This was a founding decision, not a technical workaround. The adult entertainment industry has always relied on real people putting their bodies in front of a camera—and that comes with real consequences. Exploitation, coercion, content leaked without consent, performers pressured into work they’re uncomfortable with, and careers that follow people for the rest of their lives whether they want them to or not. We chose to build a platform where none of that is possible. Every character on EnjoyMeNow is created entirely in software. No one is filmed. No one is exploited. No one’s livelihood depends on what they’re willing to do on camera. The experience is just as immersive—and no real person is harmed or compromised in the process.”
The idea that the adult industry—and “putting bodies in front of a camera”—is inherently exploitative is not only false, it’s a harmful thing to say, and it’s especially galling coming from a literal porn web toy. This entire statement is so infuriating it’s hard to know where to begin with it. These are talking points used by the most conservative, anti-porn lobbying groups and politicians on the planet to justify stripping us all of rights, here being floated by an app that makes weird, schlocky and unsatisfying 3D characters that the residents in Second Life’s least-attended sex clubs wouldn’t even find sexy.
But again, because I had the time and was feeling fresh, I asked DCBC Group to defend this statement with some data at least. “We’re not making a judgment about the adult industry or its performers,” they said. “We built a product around CGI characters, that’s a format choice, not a moral position. Some people prefer content that doesn’t involve real people. We built for them. We’ve now updated our press page to better reflect that; thank you Sam for that observation.” The page now says “EnjoyMeNow is built around computer-generated characters rather than real performers. This is a format choice—offering a new kind of private, interactive experience that doesn’t exist in traditional adult content.” Good for them for changing it.
And since users are being asked to position their dongs in front of their phone cameras on a browser-based app, I took a look at the “privacy” section of the FAQ. “Privacy is architectural, not a policy bolt-on. No app is installed. No account is required,” DCBC wrote. “All camera and motion processing runs locally on the phone—no frames, no images, no data ever leave the device. There is no cloud processing, no recording, and no persistent data stored after the session ends. When you close the tab, the adult content is automatically purged from the browser.”
I asked DCBC’s rep if they could elaborate. Well, they could at least throw more words at it: “Regarding content encryption, every 3D asset is individually encrypted at the file level, stored encrypted, transmitted encrypted, and only decrypted at render time using per-session keys that never touch the device,” they said. “There are no downloadable model files. This is a custom content protection system built specifically to prevent our CGI assets from being extracted, redistributed or changed. The specifics are proprietary, but it goes well beyond transport-layer encryption. One core goal of this architecture is ensuring no one can upload their own content to the platform. This is a closed system by design.”
“Just needless words really,” 404 Media’s privacy and security reporter Joseph Cox said about this when I showed him what DCBC said. It could easily be cut down to “we don’t allow uploads.” Which is, to be clear, for the best.
I should say here that I don’t go into these sorts of reviews assuming that I am the target audience. I’m pitched regularly by porn sites and sex toy companies on products that aren’t my personal thing; I wrote a column for years about kinks and fetishes that are not many people’s thing at all, but I wanted to better understand them and what appeal they hold for the people who love them. Maybe there are people out there who simply cannot consume content with real people in it; if that’s you, please hit me up, I would really like to hear more about that.