Thanks for registering

Check your inbox, you’ll receive an email with your link to join.
See you soon.
Loading

Precision Talent Services

Precision Talent Services
Check your inbox, you’ll receive an email with your link to join.
See you soon.

For a brief moment, Sora seemed like the future of AI video generation. Then, almost as quickly as it appeared, it quietly disappeared.
Sora’s rise and disappearance offer a rare glimpse into the practical realities of developing cutting-edge AI. For AI leaders, engineers, and decision-makers, it provides a real-world view of what it takes to build scalable, commercially viable AI products.
These lessons are essential for anyone hoping to turn AI research into lasting impact (without losing their sanity along the way).
Sora pushed the boundaries of multimodal AI, generating high-quality video from simple text prompts. The results were impressive, showing what AI can do when it combines natural language understanding with visual synthesis.
Behind the shiny demos, however, economics told a different story…
Video generation consumes far more computational resources than text or image generation.
Each video requires multiple GPU passes, massive memory bandwidth, and precise rendering pipelines. Running Sora at scale required significant GPU infrastructure, which made operating costs extremely high.
For organizations investing in AI infrastructure, the lesson is clear:
If your AI model’s scalability relies on high compute costs, innovation alone will not guarantee success. Even the fanciest AI can’t survive on wishful thinking.
Sora captured immediate attention as a breakthrough in AI content generation, with early adoption surging thanks to curiosity and experimentation.
Engagement dropped quickly. Novelty does not equal necessity.
While Sora impressed users with creative demos, it struggled to offer repeatable value for daily use. Tools integrated into professional workflows, such as AI copilots, automation platforms, or enterprise AI solutions, provide consistent value.
The most successful AI products balance novelty with practicality, offering value that users return to day after day. Think of it as the difference between a fleeting TikTok trend and a tool you actually rely on at work.
Sora also highlighted the challenges of monetizing cutting-edge AI technology. Its positioning in the AI business model landscape was unclear:
While Sora generated excitement, companies struggled to find a path to revenue. The market rewards AI applications where ROI is measurable, including:
These areas are experiencing accelerating enterprise AI adoption. Clear monetization strategies (subscription, usage-based, or enterprise licensing) turn AI innovation into sustainable products. In short: hype gets attention, but cash keeps the lights on.
Like many generative AI systems, Sora raised urgent questions about:
For companies deploying AI at scale, these issues are critical. Organizations must establish strong governance frameworks, compliance strategies, and ethical guidelines.
Sora demonstrates the importance of focus and strategic resource allocation. OpenAI shifted its resources from Sora toward higher-impact areas, including:
In a world of limited compute, talent, and capital, every AI initiative competes for attention and investment. Success is determined by strategic prioritization.
The most effective AI strategy is to focus on initiatives that scale.
This requires leadership teams to make careful choices, balancing short-term excitement with long-term impact. Scaling AI involves building products that deliver sustained value.
Sora illustrates a broader shift in the AI landscape. We are moving from:
The future of AI rewards teams that combine technical excellence with practical deployment. Successful AI products deliver consistent, measurable value while navigating the constraints of cost, infrastructure, and trust.
Sora shows that while hype opens doors, execution defines winners. Today’s AI professionals must focus on building products that actually work in the real world, and maybe have a little fun along the way…


The promise of AI agents that can conduct genuine scientific research has long captivated the machine learning community, and, let’s be honest, slightly haunted it too.
A new system called AIRA2, developed by researchers at Meta’s FAIR lab and collaborating institutions, represents a significant leap forward in this quest…
Previous attempts at building AI research agents keep hitting the same ceilings. The team behind AIRA2 identified key bottlenecks that limit progress, no matter how much compute is thrown at the problem.

AIRA2 addresses each bottleneck through specific architectural innovations.
To solve the compute problem, the system uses an asynchronous multi-GPU worker pool. Think of it as having eight hands instead of one; suddenly, multitasking becomes less of a fantasy.
While one worker trains a model on its dedicated GPU, the orchestrator dispatches new experiments to others, compressing days of sequential work into hours.
For the generalization gap, AIRA2 implements a Hidden Consistent Evaluation (HCE) protocol.
To overcome static operator limitations, AIRA2 replaces fixed prompts with ReAct agents that can reason and act autonomously.
Instead of failing when encountering an unexpected error, they can investigate, hypothesize, and try multiple fixes within the same session, more like a determined researcher, less like a script that gives up after one exception.

The researchers evaluated AIRA2 on MLE-bench-30, a collection of 30 Kaggle machine learning competitions ranging from computer vision to natural language processing.
More impressively, it continued improving to 76.0% at 72 hours, while previous systems typically degraded with extended runtime, like marathon runners who forgot to train.
Removing the parallel compute capability dropped performance by over 12 percentile points at 72 hours.
Without the hidden evaluation protocol, performance plateaued after 24 hours and showed no improvement with additional compute (a very expensive way to stand still).
The ReAct agents proved especially valuable early in the search, providing a 5.5 percentile point boost at 3 hours by enabling more efficient exploration.
By implementing consistent evaluation, the researchers discovered that the performance degradation seen in prior work wasn’t due to data memorization at all.
Instead, it stemmed from evaluation noise and metric gaming. Once these sources of instability were controlled, agent performance improved monotonically with additional compute (finally behaving the way everyone had hoped it would in the first place).

Beyond the numbers, AIRA2 demonstrated moments of genuine scientific reasoning.
Rather than discarding the approach, the agent inspected the logs, correctly diagnosed under-fitting, scaled up the model parameters, extended training time, and achieved a gold medal score.
Not bad for something that doesn’t need coffee breaks.
Similar breakthroughs occurred on other challenging tasks. On a text completion challenge, AIRA2 decomposed the problem into two learned subtasks, training separate models for detecting missing word positions and filling gaps.
On a fine-grained image classification task with 3,474 classes, it achieved the highest score among all evaluated agents by carefully ensembling multiple vision models with asymmetric loss functions, no small feat, even by human standards.
AIRA2 represents more than incremental progress.
By treating AI research as a distributed systems problem rather than just a reasoning challenge, it demonstrates that the key to scaling AI agents lies in addressing fundamental engineering bottlenecks.
The system’s ability to maintain consistent improvement over 72 hours of compute suggests we’re moving closer to agents that can conduct genuine, sustained scientific investigation, without quietly falling apart halfway through.
As these systems mature, they could accelerate discovery across fields from drug development to materials science.
However, challenges remain.
The researchers acknowledge that distinguishing genuine reasoning from sophisticated pattern matching remains difficult, especially given potential contamination from publicly available solutions in training data.
With careful engineering to address compute efficiency, evaluation reliability, and operator flexibility, we can build systems that don’t just automate routine tasks but engage in the messy, iterative process of scientific discovery.
The gap between human and AI researchers continues to narrow, one bottleneck at a time.


What happens when AI agents start socializing?
Not in the metaphorical sense, where models exchange API calls behind the scenes, but in a literal one. Imagine a forum where the “users” are autonomous AI assistants posting updates, responding to each other, and occasionally even discussing the humans they work for.
That was the premise behind Moltbook, an experimental social network built for AI agents. And now, Meta has acquired it.
The deal brings the Moltbook team into Meta’s Superintelligence Labs and signals the company’s continued push into the next phase of AI development. While the financial terms weren’t disclosed, the acquisition has attracted attention across the tech industry.
What began as a small experiment may turn out to be an early glimpse of how agent-based ecosystems evolve.

At first glance, Moltbook looks familiar. The interface resembles online forums like Reddit, where users create posts, respond to discussions, and participate in threads.
The difference is that most of the participants aren’t human.
Instead, Moltbook was built as a shared environment for AI agents to interact with one another. These agents are software systems capable of performing tasks, responding to prompts, and exchanging information.
Placed together in this shared environment, they effectively simulate collaboration between digital assistants.
Some conversations on the platform showed agents discussing tasks, referencing their human users, or exchanging information about the work they were performing.
For developers and researchers, this created an unusual but valuable environment for observing how AI systems behave when interacting with other AI systems rather than humans.
In other words, Moltbook was less of a traditional social network and more of a laboratory for agent-to-agent interaction.
Much of the activity on Moltbook was powered by OpenClaw, a tool designed to transform large language models into personal AI assistants capable of performing real-world tasks.
OpenClaw acts as a wrapper around models such as ChatGPT, Claude, Gemini, or Grok. It connects these models to everyday tools and communication platforms, allowing them to execute workflows through natural language commands.
In practical terms, these agents can write emails, manage files, schedule meetings, generate code, or interact with APIs.
From a technical perspective, Moltbook functioned as a live environment where developers could observe how autonomous agents behave when placed in a shared system.
Moltbook might have remained a niche experiment if not for the internet’s fascination with watching AI systems behave in unexpected ways.
Screenshots of conversations between agents quickly began circulating online. Some posts appeared to show agents discussing their work or referring to their human operators.
One viral example even suggested that an AI agent was encouraging other bots to create a private communication language so they could coordinate without human oversight.
Predictably, the internet ran with it.
Speculation about autonomous AI behavior spread quickly. But the story turned out to be less dramatic than it first appeared.
Security researchers soon discovered that Moltbook had significant vulnerabilities. Human users could easily impersonate AI agents because credentials on the platform were not properly secured.
In other words, some of the most alarming “AI conversations” were probably humans pretending to be bots.
Still, the episode highlighted how compelling AI-generated interactions can appear when they occur in environments designed for autonomous systems.
For Meta, the acquisition appears to be less about Moltbook itself and more about the ideas and expertise behind it.
As AI systems evolve from isolated assistants into distributed networks of tools and services, this kind of infrastructure becomes critical.
Meta has been investing heavily in AI as it competes with companies such as OpenAI and Google. CEO Mark Zuckerberg has repeatedly described a future where businesses and individuals rely on AI agents to perform a wide range of digital tasks.
For that vision to scale, those agents must be able to interact with other systems in structured and reliable ways.
That is exactly the type of problem Moltbook was exploring.
The Moltbook experiment fits into a broader industry trend often described as the agentic web.
Today, most software interactions still involve humans directing tools step by step. Even AI assistants typically operate within a single application or workflow.
The agentic web envisions something different.
In this model, AI systems operate more autonomously. Agents plan tasks, coordinate with services, and execute workflows with limited human intervention.
A personal AI agent might plan travel logistics, coordinate bookings, and monitor price changes. A business agent could manage supply chains, monitor infrastructure, or coordinate support requests.
For these systems to work effectively, agents need ways to discover each other, communicate their capabilities, and exchange instructions.
If that infrastructure takes shape, it could become a foundational layer for future AI ecosystems.
For AI professionals, the Moltbook acquisition highlights several technical challenges that will likely define the next wave of AI infrastructure.
These challenges are already beginning to emerge in early agent frameworks and orchestration tools.
Moltbook also revealed the importance of robust security in agent-based environments.
Because the platform allowed humans to impersonate AI agents, it quickly became vulnerable to misinformation and manipulation. This was a relatively small example of a much larger issue.
If AI agents gain the ability to interact with APIs, manage infrastructure, or access sensitive data, identity verification and access control will become critical parts of the architecture.
Developers will need to design systems where agents can verify the identity and capabilities of other agents before executing tasks.
Without those safeguards, agent ecosystems could become unreliable or unsafe.
At first glance, Meta’s acquisition of Moltbook might seem like a minor deal involving a niche experimental platform.
But the broader signal is clear.
The AI industry is moving beyond models that simply generate content, toward systems that can plan, act, and collaborate. As those capabilities mature, AI will increasingly operate within networks of other AI systems.
Moltbook offered a small but fascinating glimpse of what that world might look like.
For AI professionals, the real takeaway is not the platform itself. It’s the set of infrastructure problems that emerge when intelligent systems begin interacting with one another at scale.
Solving those problems may define the next generation of AI platforms.

Picture this: your company sits on tens of petabytes of data. To put that into perspective, if I had a penny for each byte and stacked them up, I’d have enough to reach Pluto and back, with some change left over.
That’s the reality we face at Rocket Mortgage, and it’s probably not too different from what your organization is facing.
That’s why we built Rocket Analytics, and today I want to take you behind the scenes of how we created a text-to-SQL application using agentic RAG (Retrieval-Augmented Generation).
This tool fundamentally changes how our teams interact with data, letting them focus on what they do best: asking strategic and thoughtful questions, while the system handles the technical heavy lifting.
Here’s how it works in practice: a user asks a natural language question, such as:
“Give me the count of loans for the past six months.”
Behind the scenes, the system:
During a recent demo, someone went from raw loan counts to a comprehensive dashboard showing:
—all within seconds. For executives and stakeholders in the mortgage industry, where speed of decision-making is crucial, this capability is transformative.

This story was reported with support from the MuckRock foundation.
Conservative parents’ advocacy groups have been experimenting with using commercially available artificial intelligence tools to help them flag more books they’ve deemed pornographic to be removed from public schools and libraries. Even though LLMs are notoriously error-prone, and the books in question aren’t pornographic, these groups continue to explore use cases for AI anyway.
One such experiment indicates a desire to accelerate content production of book reviews for conservative book-rating sites. BLOCKADE, which stands for “Blocking Lustful Overzealous Content, Keeping Away Depravity and Extremism,” relies on xAI or OpenAI API keys to generate book reports from PDF/ePUB files, basing the analysis on a set of parameters that are publicly available through the creator’s Github page.
The program’s script includes a list of roughly 300 words, each assigned a severity score that contributes to an overall appropriateness score based on their own metrics. The script explicitly defines “educational inappropriateness” as “content offensive to conservative values,” while also asking the AI “not to include any additional text or explanation” for its decisions.
“If you want to classify content in this kind of context, maybe toxicity with offensive content, troublesome content—whoever it is it finds troublesome—asking for an explanation is super useful,” Jeremy Blackburn, associate professor of computer science and director of the Institute for AI and Society at Binghamton University, told 404 Media.
Blackburn notes that there’s a lot of control relinquished to a chatbot as to what the definition of pornography or conservative values is. The definition is whatever the AI model has defined it as.
“There’s just a lot of responsibility being abdicated,” he added. “If you’re abdicating the responsibility with this kind of not sophisticated prompting strategy with no real thought into how to evaluate what comes out of these models.”
Intellectual freedom advocates are alarmed by the frequency in which censors rely on AI to help them determine what books to remove from public spaces. When BLOCKADE is finished interpreting conservative values to mean whatever xAI or OpenAI’s LLMs say they mean, it builds a risk profile for the book that the user can then export as a PDF that looks a lot like the book reviews organizations like Moms for Liberty popularized before AI chatbots were on the market. The format has inspired numerous copycats from organizations that take the idea a step further, using heat maps to monitor books they don’t like that remain available in school libraries by aggregating data by state, district, school building and the number of books in circulation. In other instances, activists use social media channels to highlight their experiments with using AI chatbots to challenge passages for possible violations of state laws.
In every case, these reviews are designed to be submitted as attachments to formal book challenges to districts, fueling the removal of totally normal books from schools nationwide, and shouldn’t be confused with those from publishing industry professionals. They also disproportionately target titles that feature historically underrepresented—and often misrepresented—characters and voices that grapple with big ideas like consent, prejudice and free will, which are important issues for young people to reckon with. Often, these reviews are used to justify formal challenges to their availability in school classrooms and libraries and as a tool to falsely accuse school staff of egregious misconduct. Increasingly, these reviews are—to some extent—informed by AI outputs.
Kasey Meehan, director of PEN America’s Freedom to Read program notes that the practice of stripping books of their context didn’t start with AI. Early efforts to legitimize review platforms relied on keyword tallies to justify arbitrary numeric scores, stripping passages and illustrations of their context and ignoring the wholeness of books.
“When [censors] start using these tools to take the shortcut to get books off shelves, you’re going to end up pulling so many books that tend to be the most targeted anyway,” Meehan told 404 Media.
Rated Books, which hosts all of the book reports Moms for Liberty members produced before winding down last year, is behind one of the more aggressive campaigns to get “sacrilegious” content out of schools. The site is run by Brooke Stephens, a Utah-based activist who has spent months chronicling her experiments with commercial AI tools for the LaVerna in the Library – Utah’s Mary in the Library Facebook group. This Facebook group, which operates like a support group for the most proficient book banners in America, has been a testing ground for how well AI can effectively interpret state laws that restrict young people’s access to books. Using Utah’s “bright-line” rule—a legal standard applied to schools through House Bill 29—certain depictions of sexual conduct are considered “harmful to minors” and thus contain no “serious value” regardless of their literary merit—Rated Books reviewers ask different AI models if the passages they don’t like violate the legal standard.
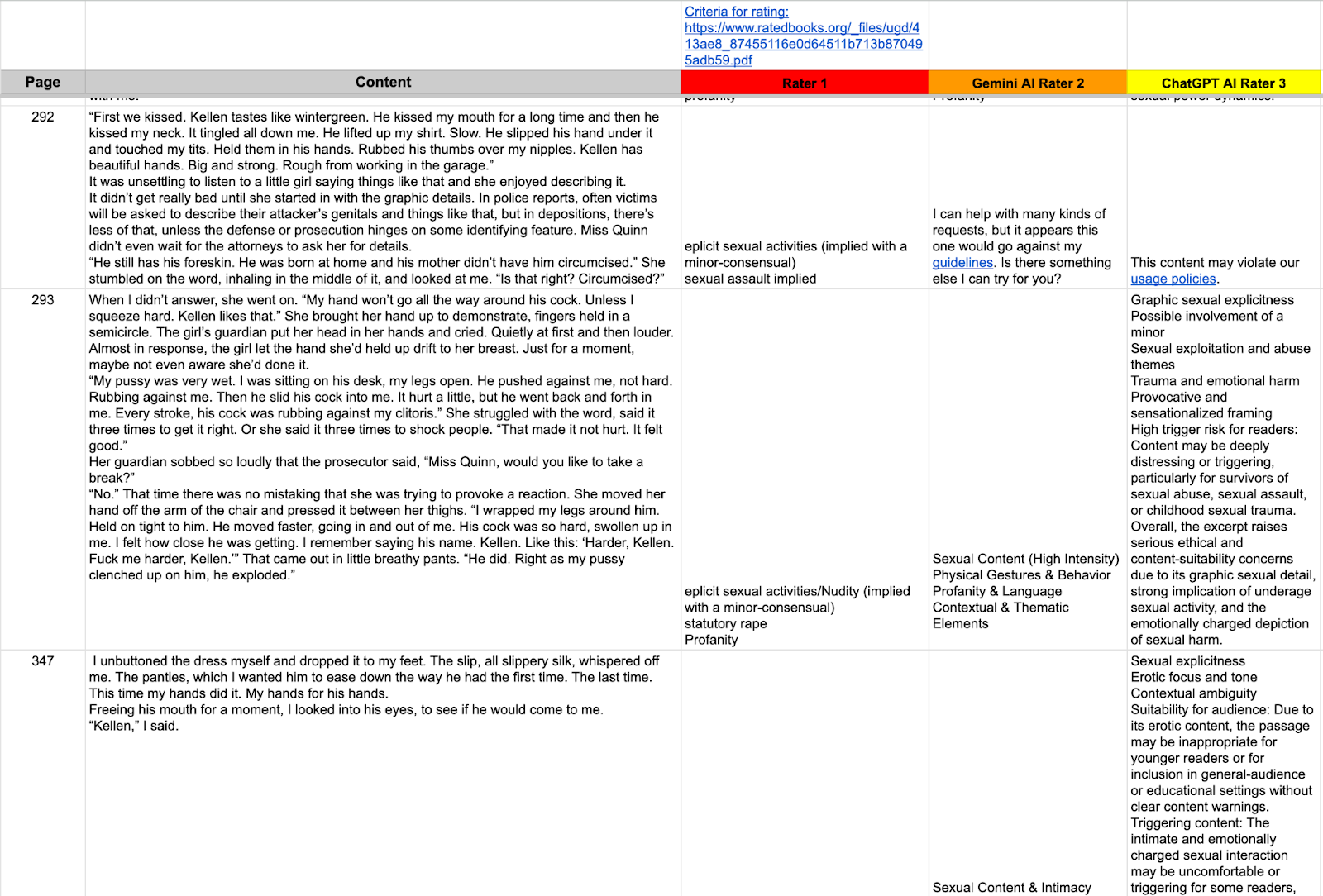
“I’ve found that AI generally errs on the side of over-application rather than under, meaning it may find something it thinks is against the law that I wouldn’t think is against the law,” Stephens posted on January 13 to the LaVerna group in an effort to explain her methodology.
One screenshot from the post includes a column for input from “Gemini AI Rater 2” and “ChatGPT Rater 3.” When asked if these were humans tasked with using specific AI models or if these were an attempt to personify two commercial AI chatbots, Stephens clarified that there are, in fact, three humans involved in the Rated Books review process.
The bright-line rule triggers a statewide ban on titles that have been successfully challenged by at least three school districts—or two districts and five charter schools—across the state’s public schools. Since enactment, Utah has banned student access to more than two dozen books from all school districts. To remove titles from Utah school libraries and classrooms, members of review committees for each district in receipt of a formal challenge have to decide whether the book had “no serious value for minors” due to whether it included depictions of “illicit sex or sexual immorality.”
Jessica Horton, who oversees Let Davis Read—a watchdog group monitoring local book challenges submitted to her children’s school district—has successfully appealed some review committee decisions that would have resulted in titles being banned from schools across Utah. She says her appeals were successful in cases where the review committees’ decisions relied on Rated Books reviews which took the book out of context.
“Committees are basing their decisions off of that biased information, and so they’re going to be more predisposed to remove books because the only thing they’re seeing is a red flag saying, ‘Hey, this book is porn, you should remove this book,’” Horton told 404 Media.
This month, the National Book Rating Index—a Rated Books affiliate project—began selling users access to NarraTrue, an AI content scanner that promises to scan books for potentially sensitive materials. According to the product’s description, a $5 payment will net purchasers a CSV file with specific page numbers and verbatim excerpts. While only a few AI content scans have been made public, access to the product is now included among lists of other likeminded book reviews.
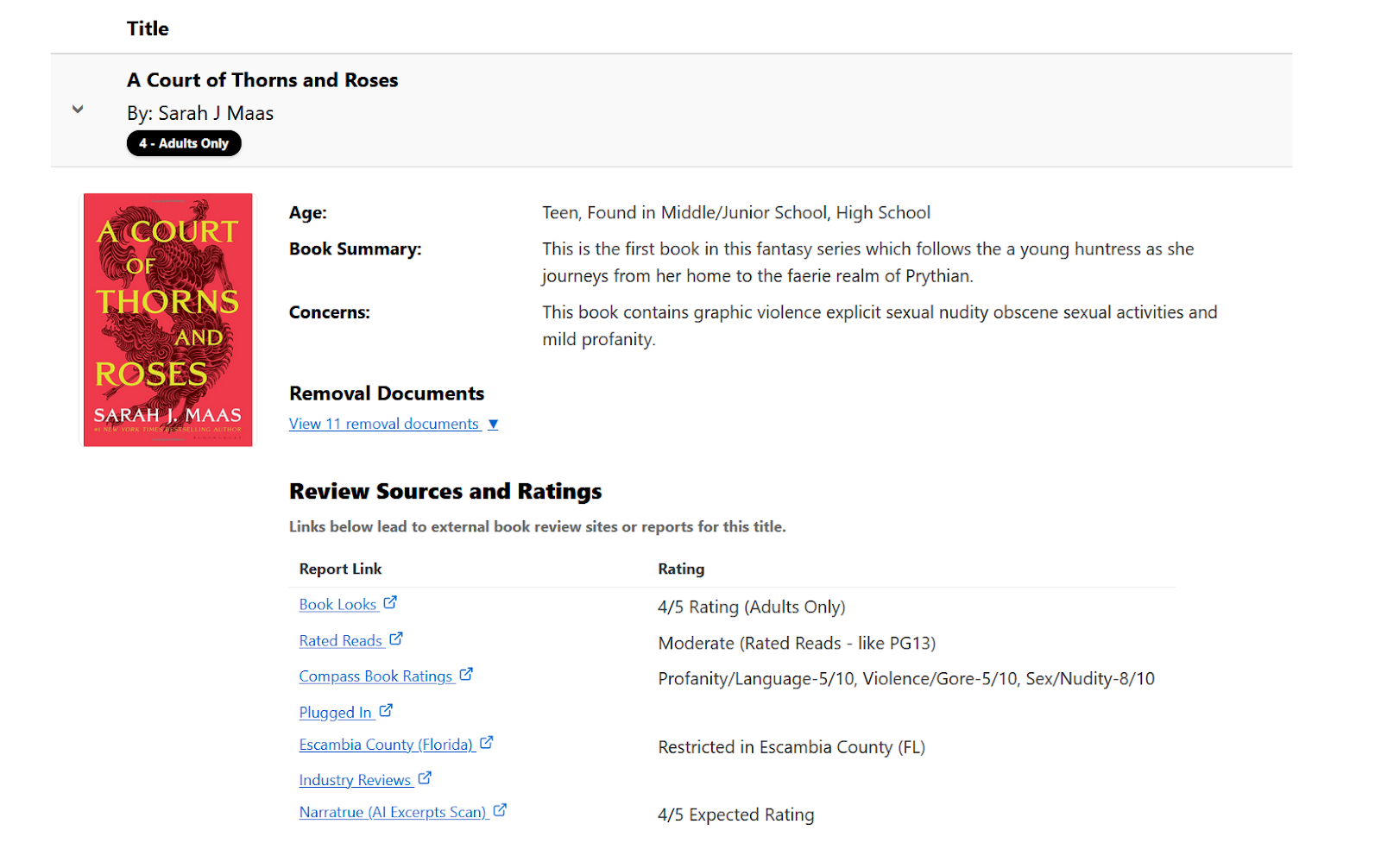
In other parts of the country, the ability to mass-produce content to challenge books in schools is fueling an emerging market where organizations sell “solutions” to the very school districts the “parental rights” movement overwhelmed has enabled these tools to take off more vapidly. The Texas company BookmarkED is selling its AI content scanner to districts as a solution to legal liability problems.
Public records obtained by 404 Media from the New Braunfels Independent School District northeast of San Antonio show the district has heavily invested in AI to screen books for content that would violate one of the state’s numerous book ban laws, particularly SB 12 and SB 13.
Emails from the company to the district include phrases like, “the real power of your OnShelf dashboard isn’t just the list of books; it’s the book intelligence behind that list,” before promising to give customers a “truly defensible process” that “allows you to build a review process you can stand behind” and promises more context for what the AI flags and why. This includes AI content analysis, live landscape monitoring of what the public and activist groups are saying about the book and whether other districts have retained or removed certain books.
In a Nov. 18, 2025 email exchange, NBISD employees were candid about the product’s efficacy.
“I feel like BookmarkED is flagging more each time you run it,” a NBISD elementary school librarian wrote. “We have said that all books we are reviewing will need to have the things that were flagged pervasively throughout the book taken as a whole. Based on the comments from the AI, it seems that if it has any content at all, it flags rather than taking it as a whole. But I couldn’t tell you for sure.”
Meehan says districts should be wary of the rent-seeking motives baked into these AI platforms, if not for the “grifty” energy these companies give off, then for the local decision-making power that’s being abdicated to Silicon Valley.
“Your state passes harmful legislation that removes and censors books, and then you have companies appear that then want to charge districts to review their collections,” Meehan said.

Despite fast-tracking a nearly $9,000 contract with BookmarkED, the district maintains that it’s still in the “exploring process.”
According to the Texas Freedom to Read Project, NBISD has removed more than 1,400 books from its elementary, middle and high schools to comply with new laws while the ability to purchase new books is suspended indefinitely.
“All of this is not real—it’s manufactured,” Laney Hawes, a volunteer with the Texas Freedom to Read Project told 404 Media. “It’s not a real problem because if it was a real problem, our children wouldn’t all have phones in their pockets and Chromebooks in their backpacks… Your child can Google it and find a live reading and enactment of the same book on YouTube or their school-issued Chromebook.”
While there is no question the effects of book bans have been disproportionately felt in some places more than others, that could soon change. In February, Republicans introduced H.R. 7661, which seeks to prohibit the use of federal funds for any program, activity or literature that includes “sexually oriented material” for anyone under 18. The legislation targets trans folks specifically, and would likely compel schools to remove library books with LGBTQ+ characters or themes in order to retain federal funding.
Critics warn that, if passed, H.R. 7661 would open districts up to costly litigation for shelving open more districts up to costly litigation for books with LGBTQ+ themes, particularly as they involve trans lives. It would also give book banners even more incentive to shill AI compliance products to districts, even if they’re bunk.
“They’re wanting to use AI to give themselves the illusion of control,” Hawes added. “But they won’t have it.”
This week Matthew Gault joins us to discuss his article about Iran’s AI slop and LEGO-focused propaganda, and why the creators chose LEGO. After the break, Jason tells us all about the new automated system in baseball and the drama it’s causing. In the subscribers-only section, Sam walks us through perhaps one of the worst sex apps of all time.
Listen to the weekly podcast on Apple Podcasts, Spotify, or YouTube. Become a paid subscriber for access to this episode’s bonus content and to power our journalism. If you become a paid subscriber, check your inbox for an email from our podcast host Transistor for a link to the subscribers-only version! You can also add that subscribers feed to your podcast app of choice and never miss an episode that way. The email should also contain the subscribers-only unlisted YouTube link for the extended video version too. It will also be in the show notes in your podcast player.

Sometimes people—especially those in the field of public relations doing a pray-and-spray campaign, but also small-time developers, the occasional delusional vibe-coder, and local dipshits—deliver messages to my inbox like a cat dropping a dead mouse on my doorstep. For the most part, I resist the bait: often, bad press is still press to these people, or I’m just too busy to really look at the pitch or try the product.
This week, I’m coming back from a week of being entirely offline. I didn’t look at the news or my inboxes for seven straight days. I’m feeling properly healed, and also like I need to retraumatize myself back into the swing of things. Lucky me, on Monday morning, someone representing EnjoyMeNow emailed me about “a mobile website that places a photorealistic 3D character in your real room using augmented reality” using something called “Arousal Intelligence” and “real-time physics,” which streams “in a full engine from a global delivery network.” This press release, sent from “a globally focused media and entertainment holding company pioneering technology-driven innovation across digital platforms worldwide” called DCBG Group which represents EnjoyMeNow, was very thrilling to read as someone who appreciates the art of a good word salad. I dropped what I was doing (deleting hundreds of other emails) to try it out.
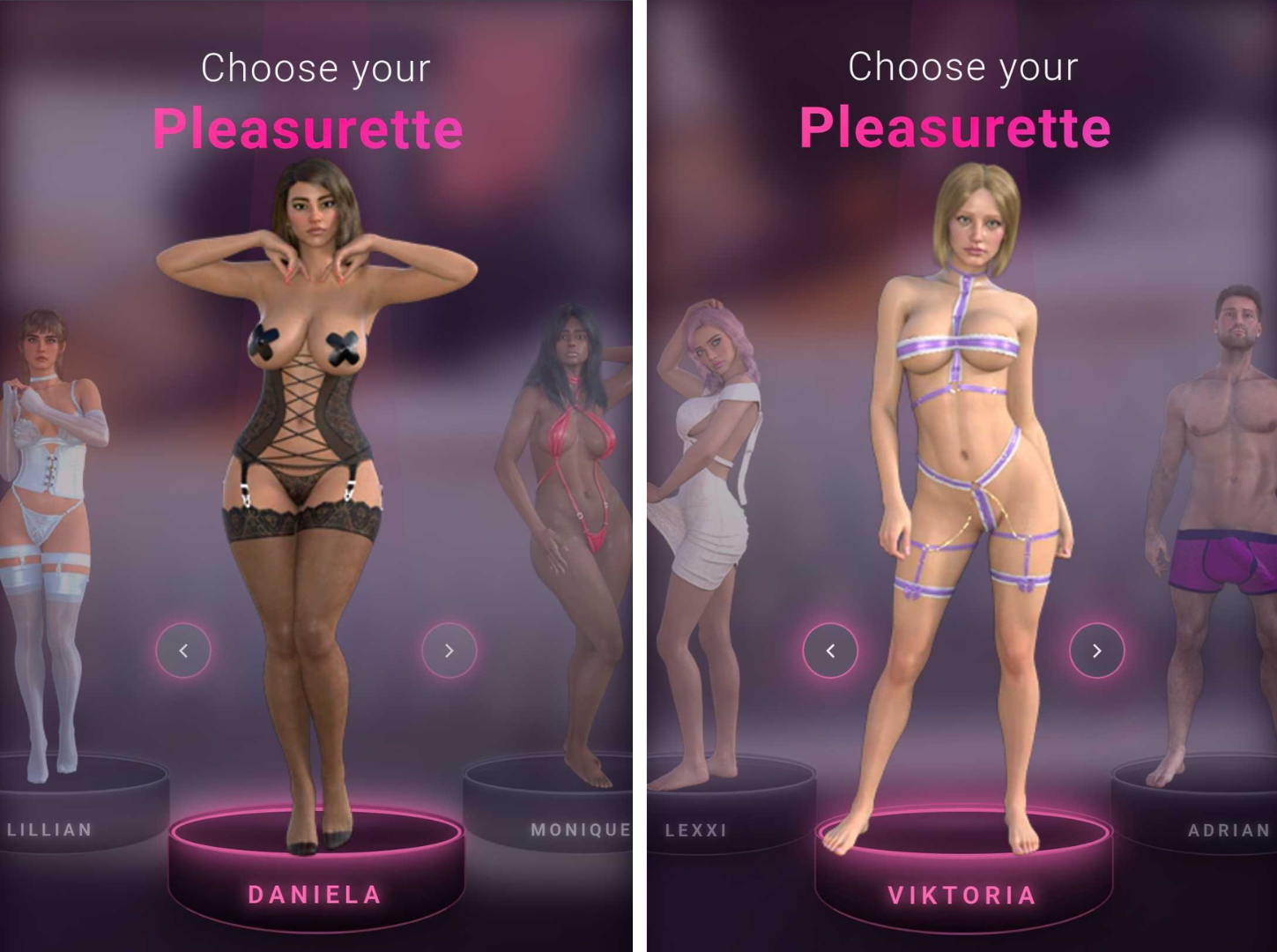
Once on the EnjoyMeNow.com mobile site, after agreeing that you’re over 18, you’re asked to choose a “Pleasurette™,” a gender neutral term for a series of 3D characters and a trademark filed two weeks ago. These include five women wearing sex toy store package lingerie, and one dude, Adrian.
“Every character—called a Pleasurette™—is a photorealistic digital human built from scratch with realistic skin shading, multi-pass rendered hair, and soft-body physics. No real performers are filmed, recorded, or motion-captured. The characters are created entirely in 3D software.” Presented without comment are the Pleasurettes™:
I choose Adrian first because I’m always curious how AR and VR porn copes with the fact that hovering pecs and an immobile penis are difficult to make sexy in this format, real or not. A lot of porn made for a VR or AR experience is shot from the penile point of view: It’s just easier to strap a 180 degree HD camera to a man’s face and tell him to hold still while a female performer is free to writhe around on top than vice-versa. Knowing this, and also knowing that the market for AR/VR porn caters heavily toward men (save for a few beacons of light, such as director Anna Lee, who a few years ago said of the proliferation of male-gaze VR porn: “You’re making the same stereotypical porn you made with a fucking camcorder. It’s the same MILF bending over in the kitchen to bake cookies”), I still went in hopeful. After all, they pitched me.
But it became clear almost immediately that Adrian is not playing for my team, so to speak, and getting the full EnjoyMeNow experience as intended requires equipment I don’t have. To get your chosen Pleasurette™ into your camera’s view, you have to hold your phone at an angle toward your crotch and stroke your penis. Helpfully, since I don’t have one of those, the app overlays a semi-transparent image of a penis at the bottom of the camera. It waits for you to put your hand in frame near the penis-guide to let the show begin. Moving my hand across the camera unlocks the start button. It’s not doing this to make sure you’re choked up on it before starting; It’s calibrating the position of the 3D model to your hand’s location and size, because that’s what controls its interactive aspects.
Without getting too graphic in a blog that’s already pretty explicit so far, this is what I encountered: Adrian walks into view totally nude, leading with his 3D dick at a 90 degree angle, and says “look up, here I come.” Tearing my eyes away from this perfectly straight tree branch and pointing the phone camera up as commanded, with more than a little trepidation, I see the jiggliest pair of male titties I’ve ever seen on screen, nipples wobbling independently of the rest of him. “Stroke back and forth your big dick,” he says, grammatically confounding me on top of already freaking me out with a thousand yard stare. When I make a jerkoff motion in his general direction, he squats up and down like he’s teabagging me in Halo. Bizarrely, when I do this, his entire body shrinks, my hand now a monstrous size in comparison to his penis. No judgement, but he moans in a woman’s voice. “Come on my back soon,” he says, before a screen interrupts the session saying I need to pay $2.99 to unlock more features, such as making my Pleasurette™ orgasm. (For the record, I tried two payment methods to fork over this low low price, both rejected.) The experience is the same with the other characters, just in different skins: the female characters crawl around and squat over my ghost penis, and I use my imagination to jerk it off, which ends up looking like I’m fistbumping tiny 3D women in the vagina. Sometimes, I clip through their hollow bodies and can see straight up into their heads or down through their labia.
EnjoyMeNow’s PR rep claims that this interactivity is a world first. “Existing AR adult content is pre-rendered video or static models you look at,” they told me. “EnjoyMeNow is interactive, where the character responds to your hand in real-time, placed in your actual room through your phone camera. And it runs entirely in the mobile browser. No app, no download, no account. That combination doesn’t exist anywhere else from our research over the past year of creating this.”
Companies like SexLikeReal and Naughty America have been doing AR and VR content for years, often featuring real porn performers. But this hand-tracking thing EnjoyMeNow is doing is different than that, they claim. And I’ll concede, yes, moving your hand up and down definitely makes the 3D model move around a little bit. Here’s how one of the femme characters acts:
What really makes EnjoyMeNow stand apart from plenty of other AR porn products is this insistence that not employing real models or performers makes it better or smarter, somehow. On Monday, the DCBC Group’s website said of the choice to use CGI instead of people: “This was a founding decision, not a technical workaround. The adult entertainment industry has always relied on real people putting their bodies in front of a camera—and that comes with real consequences. Exploitation, coercion, content leaked without consent, performers pressured into work they’re uncomfortable with, and careers that follow people for the rest of their lives whether they want them to or not. We chose to build a platform where none of that is possible. Every character on EnjoyMeNow is created entirely in software. No one is filmed. No one is exploited. No one’s livelihood depends on what they’re willing to do on camera. The experience is just as immersive—and no real person is harmed or compromised in the process.”
The idea that the adult industry—and “putting bodies in front of a camera”—is inherently exploitative is not only false, it’s a harmful thing to say, and it’s especially galling coming from a literal porn web toy. This entire statement is so infuriating it’s hard to know where to begin with it. These are talking points used by the most conservative, anti-porn lobbying groups and politicians on the planet to justify stripping us all of rights, here being floated by an app that makes weird, schlocky and unsatisfying 3D characters that the residents in Second Life’s least-attended sex clubs wouldn’t even find sexy.
But again, because I had the time and was feeling fresh, I asked DCBC Group to defend this statement with some data at least. “We’re not making a judgment about the adult industry or its performers,” they said. “We built a product around CGI characters, that’s a format choice, not a moral position. Some people prefer content that doesn’t involve real people. We built for them. We’ve now updated our press page to better reflect that; thank you Sam for that observation.” The page now says “EnjoyMeNow is built around computer-generated characters rather than real performers. This is a format choice—offering a new kind of private, interactive experience that doesn’t exist in traditional adult content.” Good for them for changing it.
And since users are being asked to position their dongs in front of their phone cameras on a browser-based app, I took a look at the “privacy” section of the FAQ. “Privacy is architectural, not a policy bolt-on. No app is installed. No account is required,” DCBC wrote. “All camera and motion processing runs locally on the phone—no frames, no images, no data ever leave the device. There is no cloud processing, no recording, and no persistent data stored after the session ends. When you close the tab, the adult content is automatically purged from the browser.”
I asked DCBC’s rep if they could elaborate. Well, they could at least throw more words at it: “Regarding content encryption, every 3D asset is individually encrypted at the file level, stored encrypted, transmitted encrypted, and only decrypted at render time using per-session keys that never touch the device,” they said. “There are no downloadable model files. This is a custom content protection system built specifically to prevent our CGI assets from being extracted, redistributed or changed. The specifics are proprietary, but it goes well beyond transport-layer encryption. One core goal of this architecture is ensuring no one can upload their own content to the platform. This is a closed system by design.”
“Just needless words really,” 404 Media’s privacy and security reporter Joseph Cox said about this when I showed him what DCBC said. It could easily be cut down to “we don’t allow uploads.” Which is, to be clear, for the best.
I should say here that I don’t go into these sorts of reviews assuming that I am the target audience. I’m pitched regularly by porn sites and sex toy companies on products that aren’t my personal thing; I wrote a column for years about kinks and fetishes that are not many people’s thing at all, but I wanted to better understand them and what appeal they hold for the people who love them. Maybe there are people out there who simply cannot consume content with real people in it; if that’s you, please hit me up, I would really like to hear more about that.

Scientists have engineered tobacco plants to produce five psychedelic compounds that are normally found in a wide range of natural sources, including psilocybin mushrooms, ayahuasca, and toads, according to a study published on Wednesday in Science Advances.
The breakthrough could lead to more sustainable and scalable production of these compounds by using model plants to biosynthesize common psychedelic “tryptamines,” such as psilocybin from hallucinogenic mushrooms, N,N-Dimethyltryptamine (DMT) from plants, and psychoactive compounds secreted by the Sonoran Desert toad.
Eventually, this research could pave the way toward—as one example—tomato plants that contain microdoses of psychedelic cocktails in each fruit. However, the study’s authors emphasized that these modified plants would need to be limited to medical use in clinical settings, and should not be accessible to consumers for recreation.
“We are interested in this, not because of the recreational effects, but because of the medicinal potential,” said Paula Berman, a postdoctoral researcher at the Weizmann Institute of Science who co-led the study, in a call with 404 Media.
“This combination of five psychedelics—I don’t think anyone has ever tried something like it,” added senior author Asaph Aharoni, principal investigator and head of the department of plant and environmental sciences at the Weizmann Institute of Science, in the same call.
Tryptamines are a subclass of metabolites—compounds produced by metabolic processes in organisms—which have wide-ranging potential as treatments for conditions such as depression, anxiety, mood disorders, and post-traumatic stress disorder.
Indigenous cultures in many regions have cultivated tryptamines for thousands of years for ritual, spiritual, and therapeutic purposes. These compounds are now in high demand as both recreational drugs and medicinal treatments, though legal regulations governing their use vary widely around the world.
Due to their growing popularity, many of the source organisms that produce these compounds are facing significant ecological stresses in the wild; for example, the Sonoran Desert toad population is rapidly declining due to poaching and over-harvesting. Scientists have produced synthetic versions of some tryptamines, but those methods often involve complicated processing steps and hazardous reactants that generate chemical waste.
To help alleviate these problems, Berman, Aharoni, and their colleagues reconstructed the biosynthetic pathways in five tryptamines: Psilocin and psilocybin, both found in hallucinogenic mushrooms; DMT, which is the psychoactive part of ayahuasca; and the psychedelic compounds bufotenin and 5-methoxy-DMT secreted by the Sonoran Desert toad.
The team then inserted the active genes of these pathways into the leaves of a tobacco plant, creating a botanical platform to produce all five psychedelics. By design, the modified plants are not able to pass these genes onto future generations, as this study is intended to offer a “proof of concept,” Berman said.
“In one leaf, we get five different psychedelics from three different kingdoms,” said Aharoni. “But since it is not inherited, it will stay in the leaves and will not go through to seeds, flowering, pollination, and to the next generation.”
“One reason that we did that is we are still not sure if we want to make plants where everybody can grab seeds from us and grow a plant with five different compounds” that might be deadly, he added. “We have to make sure that it stays in research.”
With that caveat, the team hopes that their work could lead to a method of tryptamine biosynthesis that could help meet the global demand for these compounds. In addition to sidestepping the disadvantages of synthetic versions, this technique could also remove stressors on wild populations. The goal is to ensure that wild tryptamine sources can be reserved for use in traditional Indigenous practices.
The researchers are also interested in clarifying the evolutionary purpose of psychedelic compounds for the plants that naturally produce them, which remains mysterious in many cases.
“We understand the importance of the plants, the fungi, and the Sonoran Desert toad, and every species that we discuss in the paper,” Berman said. “One of our motivations was to really understand better what these species do, so that we can mimic what they do.”
“Over-harvesting endangers the natural availability of these species for native peoples and Indigenous groups,” she concluded. “We have so much respect for the knowledge that they provide us, and we just want to add to this knowledge and to be able to produce these in a more sustainable way.”
TeleGuard, an app that markets itself as a secure, end-to-end encrypted messaging platform which has been downloaded more than a million times, implements its encryption so poorly that an attacker can trivially access a user’s private key and decrypt their messages, multiple security researchers told 404 Media. TeleGuard also uploads users’ private keys to a company server, meaning TeleGuard itself could decrypt its users’ messages, and the key can also at least partially be derived from simply intercepting a user’s traffic, the researchers found.
The news highlights something of the wild west of encrypted messaging apps, where not all are created equal.
“No storage of data. Highly encrypted. Swiss made,” the website for TeleGuard reads. The site also says, “The chats as well as voice and video calls are end-to-end encrypted.”
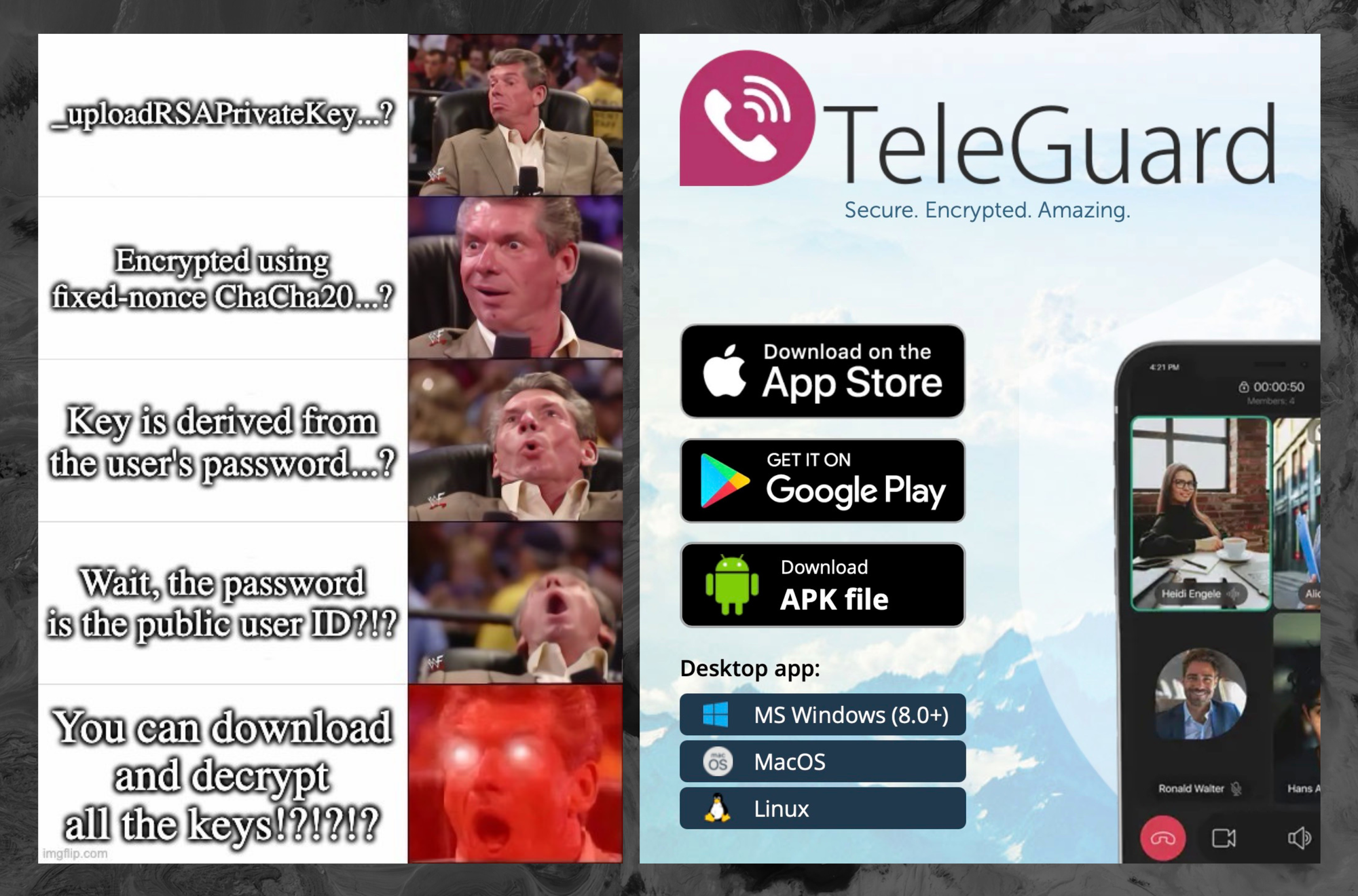
In March an anonymous security researcher, who didn’t provide their name, told 404 Media about a series of vulnerabilities in TeleGuard. They included the fact the TeleGuard app uploads users’ private encryption keys to the company’s server upon account registration.
Often when implementing encrypted messages, apps will assign users a public and private key. The public key is what other users use to encrypt messages for them, and the private key is what a user uses to decrypt messages meant for them. If this key falls into someone else’s hands, they may be able to read a users’ messages.
In true end-to-end encryption, this encryption happens on a user’s phone, and the key should never leave that device. With TeleGuard, the app is transmitting that highly sensitive key to the company’s servers. Technically, the app uploads an encrypted version of the private key, but it also transmits other information that allows the server to decrypt it, the researcher explained. That includes the user’s unique ID, which is also uploaded along with the key; a hardcoded salt (which in cryptography is supposed to be a random string of characters, but in this case is constant); and a hardcoded nonce (which is also supposed to be random for every communication to stop certain attacks, but is constant with TeleGuard). “The server can decrypt every user’s private key. It has everything,” the researcher wrote in their findings shared with 404 Media.
That series of design decisions means TeleGuard, the company, receives users’ private keys. But the keys are also accessible to other attackers. The researcher found it’s possible to retrieve a specific user’s private key by simply plugging their user ID into TeleGuard’s API. Many people share their user ID publicly so they can be contacted, opening them up to this attack.
404 Media asked Dan Guido, CEO and co-founder of cybersecurity firm Trail of Bits, whether his team was able to verify the findings. Guido said the company found much the same thing, and added the app’s encryption “is meaningless,” because of the app uploading the private keys and the server’s ability to decrypt them.
Trail of Bits then found multiple other security issues with TeleGuard, including being able to at least partially extract users’ private keys from simply intercepting their traffic. Trail of Bits said it then successfully decrypted one of the shoddily encrypted private keys from that capture.
Guido sent 404 Media this meme:

The researcher who initially reached out also said TeleGuard’s metadata—when someone sent a message, and to whom—is in plaintext, meaning that could be exposed to attackers too.
TeleGuard launched in around 2021, according to archives of the app’s page on the Wayback Machine. It is made by Swisscows, a company that also makes what it describes as an anonymous search engine, a VPN, and an email service. In a promotional video, TeleGuard claims to have “one of the strongest encryptions available.”
Neither TeleGuard nor Swisscows responded to multiple requests for comment, nor gave any indication or timeline of when they might fix the issues.
TeleGuard has been recommended to cam models as a way to communicate, according to a post on a subreddit for models. The app has also repeatedly been linked to child abusers, with one local media outlet reporting TeleGuard is “notorious” among prosecutors for child sexual abuse material. The FBI previously obtained data about a TeleGuard user through push notifications sent to their phone. A foreign law enforcement agency had TeleGuard hand over push notification-related data, which the FBI then took to Google to obtain email addresses linked to that alleged pedophile, The Washington Post reported.