How engineers at Nextdoor use Codex to build without limits
How engineers at Nextdoor use Codex with GPT-5.5 to investigate hard-to-reproduce issues, build across platforms, and focus on product outcomes.
Loading

Precision Talent Services

Precision Talent Services
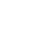

The Federal Communications Commission (FCC) wants to make it effectively impossible for people to buy what many call burner phones—a phone not explicitly linked to your identity at the point of purchase—which would impact privacy-conscious people, to domestic abuse survivors, to journalists, and many more. The FCC plans to do this by legally forcing the country’s telecoms to store a wealth of personal information about essentially all phone customers, including a government issued identification number and their physical address, alarming privacy advocates and civil rights activists who compare the measures to those from authoritarian countries where it can be difficult to buy a mobile phone plan without giving up your identity.
The proposed change would drastically shake up how people obtain phone plans in the U.S., and have all sorts of privacy and cybersecurity knock-on effects. The FCC is proposing the data collection partly as a way to combat scammers, with telecoms being required to collect other information on business and foreign customers like the intended use case of their bulk phone plan purchase and their IP address. But the changes would mean telecoms collect data on all new and renewing customers, and the FCC provides a long list of other things that the collected data could help authorities with.
“For decades, civil libertarians have looked overseas at authoritarian countries where the government requires people to register to get a mobile phone to ensure they can be tracked. We never thought that would happen here,” Jay Stanley, senior policy analyst at the American Civil Liberties Union’s (ACLU) Speech, Privacy, and Technology Project told 404 Media in an email. “But make no mistake: with this rulemaking, the government is contemplating taking away people’s ability to get a burner phone, which will hurt low-income people, domestic violence victims, and anyone else who cares about their privacy.”
In a synopsis of the proposed changes, the FCC writes, “Specifically, we seek comment on requiring originating providers to, at a minimum, obtain and retain the name, physical address, government issued identification number, and an alternate telephone number of any new and renewing customer before granting access to its services.” The goal of collecting this data, the FCC writes, is to deter some scammers from getting onto a telecom network in the first place, and so “enforcers will be better able to identify the scammers when they do.” The FCC compares the changes to the sort of data collected by banks to prevent money laundering.
One section stresses that the newly collected data would help “law enforcement to more easily identify callers that use the network to perpetuate crimes by ensuring that voice providers have accurate and complete customer information.” It goes on to ask if the data would help identify people buying and selling illicit goods; the investigation of “fraud, espionage, or influence operations that undermine national security”, and “address abuse in text messaging networks.”
“Criminals continue to leverage the anonymity provided by phone calls and texts to defraud Americans and exploit communications networks to further other crimes,” one section reads.
At the moment, the FCC is seeking comments about its proposed changes, with interested or concerned parties—think telecom companies, law enforcement, or privacy advocates—able to weigh in. But the intention of the FCC is clear: the agency wants telecoms to be legally obligated to collect much more personally identifying information on new and returning customers, linking them directly to their phone number and phone usage data. The FCC also asks whether the amount of data collected should change depending on whether a customer is seeking a prepaid or a postpaid service plan.
Multiple privacy and technology experts strongly pushed back against the proposed changes. “This proposal by the FCC will do little to combat scams and robocalls, since most people doing that will have no trouble creating fake documentation or identities,” Cooper Quintin, security researcher and senior public interest technologist with the Electronic Frontier Foundation (EFF), told 404 Media. “Given this administration’s crackdown on free expression, protest, immigrants, and women’s health we have trouble seeing this as a bold attack on freedom of communication. They want to take away our ability to make an anonymous phone call.”
Eric Null, the director of the Privacy & Data Project at the Center for Democracy & Technology, told 404 Media in an emailed statement “To address the scourge of illegal robocalls, the FCC has unfortunately proposed to force every wireless subscriber in the nation to sacrifice their privacy and give up significant personal details before receiving or renewing a wireless line. While some carriers already collect such details, there are specific circumstances where a person may need privacy and anonymity when seeking a cell phone, including if that person is a victim of domestic violence, or is a journalist or whistleblower. This proposal represents a loss of privacy across the board, and from an agency whose remit includes protecting privacy. The FCC might let a few bad apples spoil the whole bunch.”
Cape is a privacy-focused telecom company that limits the amount of data it collects on its customers. John Doyle, the company’s CEO, told 404 Media in an emailed statement “We hate robocalls and support eliminating them, but entrusting telecom carriers to effectively create a nationwide ID registry for every American with a phone is not the solution. Mobile carriers have been breached time and again because the incentives to secure trillions of dollars of legacy architecture aren’t there. Further enriching compromised telecom datasets with government ID, physical addresses, and alternate phone numbers harms our security rather than improving it.”
Given this proposal is in the comments stage, the FCC has many questions it is hoping to receive information on, such as whether “renewing” customers should be only those new to the provider, or those switching plans with their current telecom; or whether they should not allow the use of P.O. boxes or shared office locations as the required “physical address.”
The FCC did not respond to 404 Media’s request for comment. The proposal is open to comments until June 25.

The pilot phase is over, and the grace period for vague AI strategies is closing fast. The question the industry spent H1 asking (why the results fail to match the investment) is about to be answered one way or another before December.
Here are the six trends that will determine which organizations come out ahead and which ones spend Q4 in a conference room explaining why a year of AI investment produced a slightly faster way to summarize meeting notes.
A year ago, the question was whether to adopt AI.
Six months ago, it was where to start.
Right now, according to research firm Making Sense, the question is why results fall short of the investment and what to do about it before year-end.
The following six patterns are already in motion. H2 is when they demand a response.
The numbers here are striking. Anthropic’s 2026 State of AI Agents Report found 57% of organizations already running multi-step agent workflows, with 81% planning to expand into more complex use cases before year-end.
That is a long way from the “we’re piloting a chatbot” conversations that dominated 2024 and a sign that the technology has graduated from curiosity to critical path.
The practical shift in H2 is that agent deployment depth will determine competitive position more than agent capability.
A company with agents embedded in revenue-generating processes is structurally different from a company running agents at the periphery on summarization tasks. The gap between those two positions will become harder to close as the year progresses.
For teams in the second camp, the H2 priority is identifying which workflows connect directly to margin or revenue and building from there.
Generic productivity gains distributed across an entire workforce are real, but they compound far slower than agents embedded in the processes that actually move the business.
This is the trend most AI teams got exactly backwards heading into 2026, and the data now shows it. Governance spent years playing the villain in AI deployment stories: the legal team’s veto, the compliance checkbox that delayed the launch.
That reputation is now a liability for the teams that still believe it.
Salesforce’s 2026 Connectivity Benchmark, produced with Vanson Bourne and Deloitte Digital, found 89% of enterprises running AI agents across most or all of their teams. Only 54% have a formal governance framework in place. The striking part: the 54% with governance are consistently the ones scaling faster.
The mechanism is straightforward. Without audit trails, defined permissions, and clear lines of oversight, every decision to expand an agent’s scope triggers a new risk conversation. That conversation creates friction and slows deployment.
With governance infrastructure in place, expansion becomes a process. Teams add use cases, increase agent autonomy, and move into new functions without rebuilding trust from scratch each time.
H2 is the window to close this gap. PwC’s 2026 AI predictions framed it plainly: agentic workflows are spreading faster than governance models can address their unique needs. The teams that treat governance as an accelerant rather than a compliance exercise will have a material advantage by Q4.

Scaling large language models has delivered compounding returns for three years. The returns are still real, but the marginal gain per compute dollar is shrinking.
IBM’s Peter Staar put it directly in March 2026:
“People are getting tired of scaling and are looking for new ideas.”
The direction research investment is moving is toward AI that can sense, act, and learn in real-world environments.
This matters beyond the research community. Physical AI, meaning systems that combine perception, reasoning, and embodied action in unstructured environments, is where a significant portion of enterprise AI investment is heading in H2.
Warehouse automation, manufacturing quality control, and logistics coordination are the immediate commercial applications.
The technical constraint worth understanding: physical AI cannot tolerate the round-trip latency of cloud inference for closed-loop control.
Sub-100ms decision cycles require on-device inference, which means NVIDIA Jetson Orin-class hardware or equivalent at the edge, with cloud reserved for training and policy updates.
Teams evaluating physical AI deployments in H2 need to build this into their architecture assumptions from day one, well before deployment pressure makes it harder to change.
New AI models are arriving at a rate that would have seemed improbable two years ago. AI Flash Report’s tracking shows a new model release roughly every three days as of mid-2026, across providers including OpenAI, Anthropic, Google, Meta, Mistral, and a growing field of open-weight labs.
June 2026 alone saw simultaneous frontier movement: Gemini 3.5 Pro from Google, Claude Mythos from Anthropic in restricted preview, and Grok 5 from xAI after multiple delayed ship dates (some things are consistent across every era of technology).
The practical challenge for engineering teams is that benchmark improvements at the frontier rarely translate cleanly into production gains without evaluation work specific to the actual task.
A model that posts a record on GPQA Diamond may underperform a previous generation on the retrieval-augmented generation pipeline your team actually runs.
The teams that chase frontier releases on benchmark headlines will spend H2 in an expensive churn cycle.
The buy-vs-build calculus shifted faster than most technology roadmaps assumed.
Retool’s 2026 Build vs. Buy Report, covered by Newsweek, found 35% of enterprises have already replaced at least one SaaS tool with something they built internally, with 78% expecting to build more before year-end.
The driver is economics, full stop. AI coding tools, particularly Cursor and GitHub Copilot, have compressed what previously required months of engineering effort into days of prototyping.
The classic argument for buying off-the-shelf, that building takes too long and costs too much, has had its legs quietly knocked out from under it.
The organizations pulling ahead in H2 are making this distinction deliberately rather than defaulting to either side.
Here are the signals that a workflow is a candidate for a custom build:
This happened once before, and the teams that lived through it remember the feeling. Teams that built customer support on decision-tree chatbots in 2021 and 2022 had a reasonable bet on the technology available to them.
When LLMs arrived, those systems went from adequate to visibly limited in roughly eighteen months, and the organizations that had hardcoded every assumption into the architecture paid a steep migration price.
In practice, this means two things. First, abstract model calls behind an interface layer rather than hardcoding provider-specific SDKs directly into business logic.
Second, maintain a lightweight internal benchmark suite for your core workflows so that evaluating a new model is a process that takes hours rather than a project that takes weeks.
Teams without this infrastructure will face a recurring tax every time the frontier shifts, which in H2 2026 will be often.

The throughline across all six trends is the same: depth beats breadth. The organizations that spent H1 deploying AI widely across surface-level tasks will hit a ceiling in H2 that a shiny new model release will do precisely nothing to fix.
The ones that embedded AI into the processes that matter, built governance to scale it, and architected for change will find the second half of 2026 considerably more productive.
The competitive gap that opens in H2 will be harder to close in 2027 than it would be to close right now. Which is, admittedly, what people said about H1.
Six trends is a tidy number, and reality will add a few messier ones before December.
What the data consistently points to, across governance research, agent deployment surveys, and the physical AI investment narrative, is that the organizations in the best position heading into H2 treated the first half of 2026 as a foundation rather than a finish line.
The industry has a reliable habit of declaring each new capability wave as the one that finally changes everything.
The more useful frame is that each wave raises the floor. The floor in H2 2026 is higher than it was six months ago, and the teams operating comfortably above it right now earned that position by making unglamorous infrastructure decisions when everyone else was busy writing LinkedIn posts about the future of work.
A surveillance company plans to add sensors to automatic license plate readers (ALPRs) that would mean the devices, as well as capture the license plate of passing vehicles, would also sweep up unique identifiers of mobile phones, wearables, and other Bluetooth-enabled devices in those cars, potentially letting law enforcement identify specific drivers or passengers.
The technology, called SignalTrace, would turn ALPR cameras from devices focused on tracking cars to ones that can more readily track the location of particular people. ALPR cameras have become a commonly deployed technology all across the U.S.; SignalTrace would make some of those cameras capable of collecting much more data.
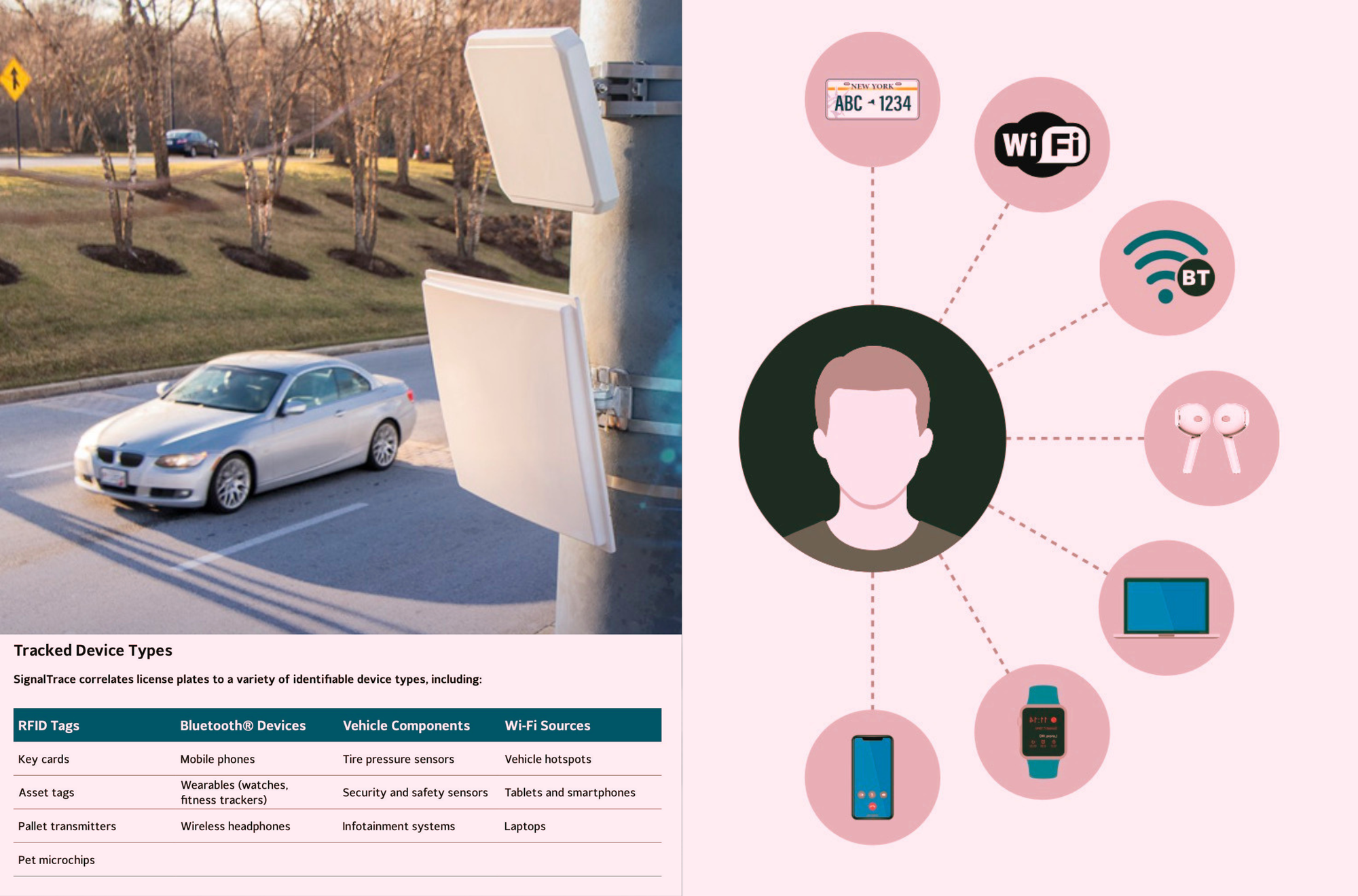
SignalTrace “bridges license plate recognition data with sensor-captured device identifiers—such as those from mobile phones, Bluetooth wearables, and vehicle systems—to create a unique, trackable ‘electronic fingerprint’ for investigative use,” according to a product sheet describing the tool, written by surveillance company Leonardo, which advertises SignalTrace.
The sort of data Leonardo says SignalTrace can sweep up includes the RFID tags in key cards and pet microchips; devices with Bluetooth such as wireless headphones, fitness trackers, and mobile phones; components of a car like tire pressure sensors and infotainment systems; and Wi-Fi sources such as vehicle hotspots and laptops, according to the product sheet.


Screenshots of the product sheet, available here.
The idea is to correlate these unique device identifiers to a license plate. If a Leonardo camera detects a license plate and sees where a vehicle was at a specific time, it can then allegedly link those unique device identifiers to it.
The sheet suggests SignalTrace collects this data for it to be searched by law enforcement much later. One line says SignalTrace “stores device and correlation data securely in the EOC [Enterprise Operations Center] for future queries and analysis.”
“When multiple devices consistently move together with a vehicle, SignalTrace’s algorithms link them to that vehicle’s license plate and time-stamped location data. This correlation provides investigators with another layer of actionable intelligence, even if a suspect changes or removes a plate,” the sheet reads.
Leonardo sells ALPR cameras and communications equipment to law enforcement, border security, and other government agencies. Its U.S. arm has contracts with U.S. Special Operations Command and the General Services Administration, according to procurement records maintained by the transparency website Widely Reported.
404 Media has previously covered how other ALPR companies want to bridge the gap between vehicle and occupant. Flock, for example, has created a system called Nova, to supplement license plate data with other pieces of information. 404 Media revealed the company planned to use hacked data from previous data breaches to “jump from LPR to person.” Flock said it decided to not use hacked data in Nova after 404 Media’s coverage and internal pressure.
Leonardo did not immediately respond to a request for comment.

Microsoft has shut down a wave of its own repositories on GitHub, including those related to Azure and AI coding agents, as it investigates a data breach, according to research from cybersecurity researchers and a statement given to 404 Media by Microsoft. Hackers planted malware that would harvest peoples’ credentials when they opened it in AI coding tools like Claude Code or Gemini CLI, according to one set of researchers.
The exact contours of the breach are unclear, but researchers say Microsoft has disabled more than 70 of its own repositories, and pointed to a particular package that was previously compromised.
“We have temporarily removed some repositories as we investigate potential malicious content,” Microsoft told 404 Media in an emailed statement on Monday.
At the time of writing, various GitHub repositories reads:
“This repository has been disabled. Access to this repository has been disabled by GitHub Staff due to a violation of GitHub’s terms of service. If you are the owner of the repository, you may reach out to GitHub Support for more information.”
Last week, cybersecurity website OpenSourceMalware.com, which acts as a clearing house for indicators of supply chain attacks so defenders can secure their own networks, and which also publishes its own write-ups, wrote about the mass disabling of Microsoft GitHub repositories.
“GitHub disabled 73 Microsoft repositories across four of its GitHub organizations—the entire Azure Functions org, the whole Durable Task family, and a row of AI sample apps—in a 105-second sweep on June 5,” the website wrote on Friday.
Is it very unusual for any company, let alone Microsoft, to disable so many of its own repositories in one go. They include 49 related to Azure, Microsoft’s cloud computing arm, and some concerning AI agents.
The shutdown repositories also include ones related to durabletask, a Microsoft development tool.
Researchers from StepSecurity wrote on Friday that the GitHub closures came after a malicious commit was pushed to the durabletask repository. That attack planted configuration files that would harvest peoples’ credentials when they opened the repository in Claude Code, Gemini CLI, Cursor, or VS Code, StepSecurity wrote.
Hackers from the group TeamPCP previously compromised Microsoft’s durabletask, publishing three malicious versions of the tool in May. TeamPCP has performed a wealth of supply chain attacks in the first half of this year, impacting hundreds of organizations, WIRED reported.
In practice, this means that any GitHub actions that used those repositories will no longer function. And coupled with the statement and research, indicates Microsoft did not fully protect itself and its users after the earlier compromise.
“Why is this mentioned nowhere?” one commentator on a Microsoft forum thread discussing one of the repository closures writes.

Welcome back to the Abstract! Here are the studies this week that balanced it out, performed evasive maneuvers, decorated a love shack, and bred inside bones.
First, scientists discover a new “triple symmetry” on Earth that nobody can explain. Then: female dolphins keep tabs on coercive males, bowerbirds turn urban trash into urbane treasure, and the housing opportunities provided by dead dinos.
As always, for more of my work, check out my book First Contact: The Story of Our Obsession with Aliens, or subscribe to my personal newsletter the BeX Files.
Zhang, Jianhao et al. “Earth’s east–west albedo symmetry.” Nature.
Scientists have discovered an unexplained “triple symmetry” in Earth’s albedo, meaning its ability to reflect sunlight. The finding deepens the mystery of Earth’s oddly-balanced brightness contrasts, which has been well documented in the near-perfectly matched albedos of the northern and southern hemispheres, despite the very different geographies of these two halves of the planet.
Researchers led by Jianhao Zhang of the University of Colorado Boulder now report the existence of “a unique and persistent east-west (E-W) albedo symmetry: the 27° E meridian divides the planet into an Eastern Hemisphere and a Western Hemisphere that reflect nearly identical amounts of sunlight,” according to the team’s study.
The hemispheres bisected by the 27° E meridian line have nearly-identical amounts of ice-free ocean, cloud cover, as well as planetary albedo, distinguishing this phenomenon as a “triple symmetry” that is distinct from the equatorially divided north-south symmetry, which only has matching albedos.
Zhang and his colleagues discovered the triple symmetry by examining 25 years of data (2001–2025) captured by NASA’s Clouds and the Earth’s Radiant Energy System (CERES) program. The satellite-mounted instruments measure the amount of solar energy Earth reflects back into space.
The east-west symmetry persisted over this dataset, with its greatest variations linked to the El Niño-Southern Oscillation (ENSO). For this reason, the team emphasized that the symmetry is essential to accurate projections on a rapidly warming world. Currently, “all models fail to capture…the triple-symmetry feature,” a problem that may be ”contributing to the persistent uncertainty in climate projections,” according to the study.
As for what causes this symmetry, nobody knows. It could be just a strange coincidence, or even weirder, an unknown process of planetary equilibrium. As we reported last year, the north-south albedo symmetry may be fading as both hemispheres get darker, with more pronounced effects in the North, so scientists are leaning toward the weird coincidence hypothesis.
“We cannot yet rule out the possibility that these hemispheric symmetries are simply coincidental features of the present climate state,” the team said in the study. “The importance of the E–W symmetry discovery, however, is beyond the identification of another ‘sweet spot’ of the Earth system.”
“It offers a powerful…constraint on state-of-the-art [Earth system models] and, more broadly, on our fundamental understanding of the Earth climate system,” the researchers concluded.
In other news…
Female dolphins avoid sexually coercive males by keeping track of their signature whistles, according to scientists who observed how wild female Indo-Pacific bottlenose dolphins reacted to recorded playbacks of male vocalizations in the waters of Shark Bay, Australia.
To secure mating opportunities, coercive males “will bite, hit, or charge the female, chase her…and produce threat vocalizations termed pops—all to intimidate the female and control her movements,” said researchers led by Alice Bouchard of the University of Bristol. “Indeed, pops are only produced by males” and act “as an agonistic ‘come-hither’ signal, inducing the female to stay close to the popping male.”
Who could have guessed the term “popping male” could be so ominous? No wonder female dolphins keep them at fin’s length. Along those lines, the team found that females showed aversive responses to the recorded whistles of males known to have been coercive in the past.
Females appear to use “individual vocal labels to guide reproductive decision-making based on their experience of individual male behavior,” according to the study. Call it a whistle campaign.
For every popping dolphin in the seas, there is a lover bird in the trees. For the male great bowerbird (Chlamydera nuchalis), the key to attracting females isn’t biting or coercion, but the construction of elaborate shelters called bowers decorated with carefully selected trinkets for the enjoyment of potential mates.
Scientists have now discovered that urban bowerbirds may have an edge in their game compared to their rural counterparts, thanks to the dazzling decor options that can be upcycled from their city environments.

The team catalogued nearly 4,000 decorations collected by Australian bowerbirds at Dreghorn Cattle Station, the rural site, and their urban counterparts in, literally, Townsville (the children’s book writes itself). The results suggest that “urban males may represent an adaptive change to a more attractive display, and that rural males are restricted in their displays by the materials available in their environment.”
“The two most common decorations in rural areas were green glass and green leaves/seeds, and in urban areas the two most common decorations were green glass and red wire,” said authors Caitlin F. Evans and Laura A. Kelley of the University of Exeter, “Decorations on urban bowers were over 10 times more likely to be anthropogenic…than decorations on rural bowers.”
While the city birds may have an easier time finding flashy ornaments, the use of plastics and other human-generated trash have posed dangers, such as entanglement or ingestion, for other species, though it has not been confirmed in bowerbirds. Glass shards and scarlet wires may make for beautiful displays, but never discount the risk of fatal attraction.
We’ll end, as all things should, with a 30,000-pound feast. Titanosaurs, the largest family of animals ever to walk on land, were so enormous as adults that predators basically left them alone (though they made for easy pickings as youngsters).
But once these dinosaurs shuffled off their metric-ton mortal coils, their corpses were devoured by scavengers—including small insects that bore into their bones, leaving permanent structures in their fossilized remains, known as “ichnofacies.”

In a new study, paleontologists mapped out the pits, holes, burrows, and trails etched into Cretaceous titanosaur bones deposited in the exquisitely well-preserved Lo Hueco site in Cuenca, Spain. In particular, the results revealed idiosyncratic pupation chambers likely dug out by flesh-eating Cubiculum beetles to deposit larvae. The structures suggest that the dead dinos were exposed to open air for weeks on ancient floodplains as beetles were born and bred in their bones.
“Given the size of the titanosaurs…it is likely that at least part of their carcasses remained dry for long periods of time (several days and even months), and hence, to constitute a perfect scenario for insect colonization,” said researchers led by Zain Belaústegui of the University of Barcelona. “The large size of the carcasses involved (i.e., tons of decaying organic matter) may support specific and stable ecosystems during long periods of time.”
In other words, titanosaur skeletons served as luxury mansions long after their death, with beetle colonies etching in the equivalent of “we were here” notes that have lasted for 70 million years.
Thanks for reading! See you next week.
On April 30, the MIT Schwarzman College of Computing’s Social and Ethical Responsibilities of Computing (SERC) initiative hosted a full-day research symposium examining how artificial intelligence is shaping the world and its implications for society.
The symposium included research talks by SERC’s latest seed grant recipients on topics such as air pollution forecasting and responsible computer vision deployment, panels on AI alignment and AI in education, and a keynote address by Jon Kleinberg PhD ’96, the Tisch University Professor of Computer Science and Information Science at Cornell University. The event also featured a poster session, where student researchers showcased projects they worked on throughout the year as SERC Scholars.
“There is so much amazing research being done at MIT on how AI and computing can be forces for good that benefit humanity. It was inspiring to see so much community interest in all this cutting-edge work,” said Brian Hedden, co-associate dean of SERC and professor of philosophy, who holds an MIT Schwarzman College of Computing shared position with the Department of Electrical Engineering and Computer Science (EECS).
“As computing and AI become increasingly embedded in nearly every dimension of society, SERC’s mission is to help ensure that ethical reflection and technical progress advance together,” said Nikos Trichakis, co-associate dean of SERC and the J.C. Penney Professor of Management. “This year’s symposium highlights the extraordinary range of work underway across MIT, and creates a forum for our community to engage deeply with the responsibilities that come with shaping the future of computing.”
Aligning AI with human values — and what values those might be
The challenges with AI alignment and moral meshing lie in the ethical questions of how to instill “human values” onto a very powerful and rapidly changing technology. Who makes the decision on what values and rationalities are included in an ethical framework? How does one account for distortion when translating these values from user to machine?
These questions, among others, were posed by Dylan Hadfield-Menell, associate professor of EECS, during a panel he moderated that brought together an interdisciplinary group of speakers.
Iason Gabriel, a philosopher and research scientist at Google DeepMind, used the example of a judge to illustrate his point. “You want a judge to have good character, but to still interpret the rules. A reasonable person, though not necessarily the best person who ever lived. When it comes to AI, it’s not appropriate to model it as perfect. AI should be doing what we tell it to do, while using its character to interpret according to our moral values.”
Bailey Flanigan, assistant professor of political science in a shared appointment with the MIT Schwarzman College of Computing in EECS, took this a step further. To her, the most important problem to AI alignment is “resolving fundamental questions on who is entitled to govern different types of AI systems in the first place.”
Joining Flanigan on the panel was Bernado Zacka, associate professor of political science. Given the momentum of AI and complex institutional designs, Zacka expressed, “one of the most urgent problems is understanding the wisdom contained in the systems we are replacing, and why they function the way they do.”
As deployment pressure increases, it can often feel like people are building the plane as they fly it, although the panelists overall seemed optimistic about the trajectory of AI alignment, emphasizing how crucial human components are to shaping these systems.
Offloading versus uplifting
As students across all levels of education begin to use AI, questions arise on whether there’s a way to ethically incorporate AI tools while maintaining academic accuracy and rigor. At a panel on AI and education, MIT faculty and Marta McAlister, the director of Gemini for Education, explored how AI is already being used in their classrooms and discussed ways it can support learning while remaining aligned with instructional and curricular goals.
Professors Eric Klopfer and Samuel Madden, co-chairs of MIT’s Ad Hoc Committee on AI Use in Teaching, Learning, and Research Training, homed in on a central dilemma of whether AI is being used to offload work, rather than being used to help scaffold the concepts being taught.
Madden, faculty head of computer science in EECS and the MIT College of Computing Distinguished Professor, described the process of cognitive struggle, whereby learning is done through a series of trials and failures. He said, “students now, when they hit that wall, their first instinct is to ask AI. They don’t see this as excelling in this process, and they haven’t actually acquired the skill you’re assessing.” The question then becomes how instructors maintain the process of cognitive struggle so it provides just enough of a challenge to combat the urge to use AI.
Klopfer, who serves as director of the Scheller Teacher Education Program and the Education Arcade at MIT, echoed similar sentiments, in that critical thinking is no longer becoming a crucial step in the output of the work. Regarding where to start in keeping material just challenging enough, Klopfer suggested examining the curriculum as a whole. “Some core content has to go. We keep adding, instead of parsing or pruning,” he said.
Moderator Justin Reich, director of the Teaching Systems Lab and an associate professor in the Comparative Media Studies Program/Writing, noted that while teens know that AI is bad, it doesn’t necessarily stop their AI usage. However, by inviting them into the discussion on how AI is implemented and incorporating a more reflective exchange with instructors, students could be more equipped to choose how they use these tools and why.
Regardless, AI tools and their implementation should not be treated as a one-size-fits-all policy. Pat Pataranutaporn, the Asahi Broadcasting Corporation Career Development Professor of Media Arts and Sciences and head of the Cyborg Psychology research group at the MIT Media Lab, said, “AI is not just one thing. It can and should be designed differently to promote things like creativity and critical thinking. What we measure, and how, shouldn’t be about getting the answer right. We should think about it would really mean for a student to learn these days.”
Is mimicking human reasoning just as good as the real thing?
With a slide deck that included chess grandmasters and film references, Kleinberg’s keynote address, titled “AI’s Models of the World, and Ours,” evaluated instances where AI systems have inadvertently set us up to fail due to a mismatch between the system’s model of the world and ours.
To illustrate this point, Kleinberg used chess, where modern chess engines can compete at superhuman levels, but when paired with human partners, their strategies aren’t understandable or inferable to their human counterpart. These human handoffs would then lead to confusion. Kleinberg used the example of “The Fellowship of the Ring,” where Gandalf, a powerful wizard, entrusts a highly dangerous and important quest to a ragtag group of adventurers. For those familiar with the story, the group is unexpectedly left without Gandalf’s guidance, sending them into a temporary bout of very serious turmoil.
When the chess engine hands a turn over to its human partner, the human struggles to pick up on the predictive move pattern that the engine has been following up until this point. “The danger of human-algorithm teams is that when the human takes over, the algorithm knows what it wants to do next, but the human doesn’t,” explained Kleinberg.
These analogies showcase the differences in the ways AI understands a world — through predictive simulations, pattern recognition, and constraints — to mimic human reasoning versus the innate, embodied knowledge that comes with the human experience, and whether these systems truly understand the worlds in which they’re operating. But the question remains that if the game still results in a checkmate, does it matter?